
目标
嗯,我们知道搜索或浏览网站时会有很多精美、漂亮的图片。
我们下载的时候,得鼠标一个个下载,而且还翻页。
那么,有没有一种方法,可以使用非人工方式自动识别并下载图片。美美哒。
那么请使用python语言,构建一个抓取和下载网页图片的爬虫。
当然为了提高效率,我们同时采用多线程并行方式。
思路分析
Python有很多的第三方库,可以帮助我们实现各种各样的功能。问题在于,我们弄清楚我们需要什么:
1)http请求库,根据网站地址可以获取网页源代码。甚至可以下载图片写入磁盘。
2)解析网页源代码,识别图片连接地址。比如正则表达式,或者简易的第三方库。
3)支持构建多线程或线程池。
4)如果可能,需要伪造成浏览器,或绕过网站校验。(嗯,网站有可能会防着爬虫 ;-))
5)如果可能,也需要自动创建目录,随机数、日期时间等相关内容。
如此,我们开始搞事情。O(∩_∩)O~
环境配置
操作系统:windows 或 linux 皆可
Python版本:Python3.6 ( not Python 2.x 哦)
第三方库
urllib.request
threading 或者 concurrent.futures 多线程或线程池(python3.2+)
re 正则表达式内置模块
os 操作系统内置模块
编码过程
我们分解一下过程。完整源代码在博文最终提供。
伪装为浏览器
import urllib.request
# ------ 伪装为浏览器 ---def makeOpener(head={ 'Connection': 'Keep-Alive', 'Accept': 'text/html, application/xhtml+xml, */*', 'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2', 'Connection': 'keep-alive', 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:57.0) Gecko/20100101 Firefox/57.0' }): cj = http.cookiejar.CookieJar() opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj)) header = [] for key, value in head.items(): elem = (key, value) header.append(elem) opener.addheaders = header return opener 获取网页源代码
# ------ 获取网页源代码 ---# url 网页链接地址def getHtml(url): print('url='+url) oper = makeOpener() if oper is not None: page = oper.open(url) #print ('-----oper----') else: req=urllib.request.Request(url) # 爬虫伪装浏览器 req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64; rv:57.0) Gecko/20100101 Firefox/57.0') page = urllib.request.urlopen(req) html = page.read() if collectHtmlEnabled: #是否采集html with open('html.txt', 'wb') as f: f.write(html) # 采集到本地文件,来分析 # ------ 修改html对象内的字符编码为UTF-8 ------ if chardetSupport: cdt = chardet.detect(html) charset = cdt['encoding'] #用chardet进行内容分析 else: charset = 'utf8' try: result = html.decode(charset) except: result = html.decode('gbk') return result 下载单个图片
# ------ 根据图片url下载图片 ------# folderPath 定义图片存放的目录 imgUrl 一个图片的链接地址 index 索引,表示第几个图片def downloadImg(folderPath, imgUrl, index): # ------ 异常处理 ------ try: imgContent = (urllib.request.urlopen(imgUrl)).read() except urllib.error.URLError as e: if printLogEnabled : print ('【错误】当前图片无法下载') return False except urllib.error.HTTPError as e: if printLogEnabled : print ('【错误】当前图片下载异常') return False else: imgeNameFromUrl = os.path.basename(imgUrl) if printLogEnabled : print ('正在下载第'+str(index+1)+'张图片,图片地址:'+str(imgUrl)) # ------ IO处理 ------ isExists=os.path.exists(folderPath) if not isExists: # 目录不存在,则创建 os.makedirs( folderPath ) #print ('创建目录') # 图片名命名规则,随机字符串 imgName = imgeNameFromUrl if len(imgeNameFromUrl) < 8: imgName = random_str(4) + random_str(1,'123456789') + random_str(2,'0123456789')+"_" + imgeNameFromUrl filename= folderPath + "\\"+str(imgName)+".jpg" try: with open(filename, 'wb') as f: f.write(imgContent) # 写入本地磁盘 # if printLogEnabled : print ('下载完成第'+str(index+1)+'张图片') except : return False return True 下载一批图片(多线程/线程池模式皆支持)
# ------ 批量下载图片 ------# folderPath 定义图片存放的目录 imgList 多个图片的链接地址def downloadImgList(folderPath, imgList): index = 0 # print ('poolSupport='+str(poolSupport)) if not poolSupport: #print ('多线程模式') # ------ 多线程编程 ------ threads = [] for imgUrl in imgList: # if printLogEnabled : print ('准备下载第'+str(index+1)+'张图片') threads.append(threading.Thread(target=downloadImg,args=(folderPath,imgUrl,index,))) index += 1 for t in threads: t.setDaemon(True) t.start() t.join() #父线程,等待所有线程结束 if len(imgList) >0 : print ('下载结束,存放图片目录:' + str(folderPath)) else: #print ('线程池模式') # ------ 线程池编程 ------ futures = [] # 创建一个最大可容纳N个task的线程池 thePoolSize 为 全局变量 with concurrent.futures.ThreadPoolExecutor(max_workers=thePoolSize) as pool: for imgUrl in imgList: # if printLogEnabled : print ('准备下载第'+str(index+1)+'张图片') futures.append(pool.submit(downloadImg, folderPath, imgUrl, index)) index += 1 result = concurrent.futures.wait(futures, timeout=None, return_when='ALL_COMPLETED') suc = 0 for f in result.done: if f.result(): suc +=1 print('下载结束,总数:'+str(len(imgList))+',成功数:'+str(suc)+',存放图片目录:' + str(folderPath)) 调用例子
如百度贴吧为例
# ------ 下载百度帖子内所有图片 ------# folderPath 定义图片存放的目录 url 百度贴吧链接def downloadImgFromBaidutieba(folderPath='tieba', url='https://tieba.baidu.com/p/5256331871'): html = getHtml(url) # ------ 利用正则表达式匹配网页内容找到图片地址 ------ #reg = r'src="(.*?\.jpg)"' reg = r'src="(.*?/sign=.*?\.jpg)"' imgre = re.compile(reg); imgList = re.findall(imgre, html) print ('找到图片个数:' + str(len(imgList))) # 下载图片 if len(imgList) >0 : downloadImgList(folderPath, imgList) # 程序入口if __name__ == '__main__': now = datetime.datetime.now().strftime('%Y-%m-%d %H-%M-%S') # 下载百度帖子内所有图片 downloadImgFromBaidutieba('tieba\\'+now, 'https://tieba.baidu.com/p/5256331871') 效果


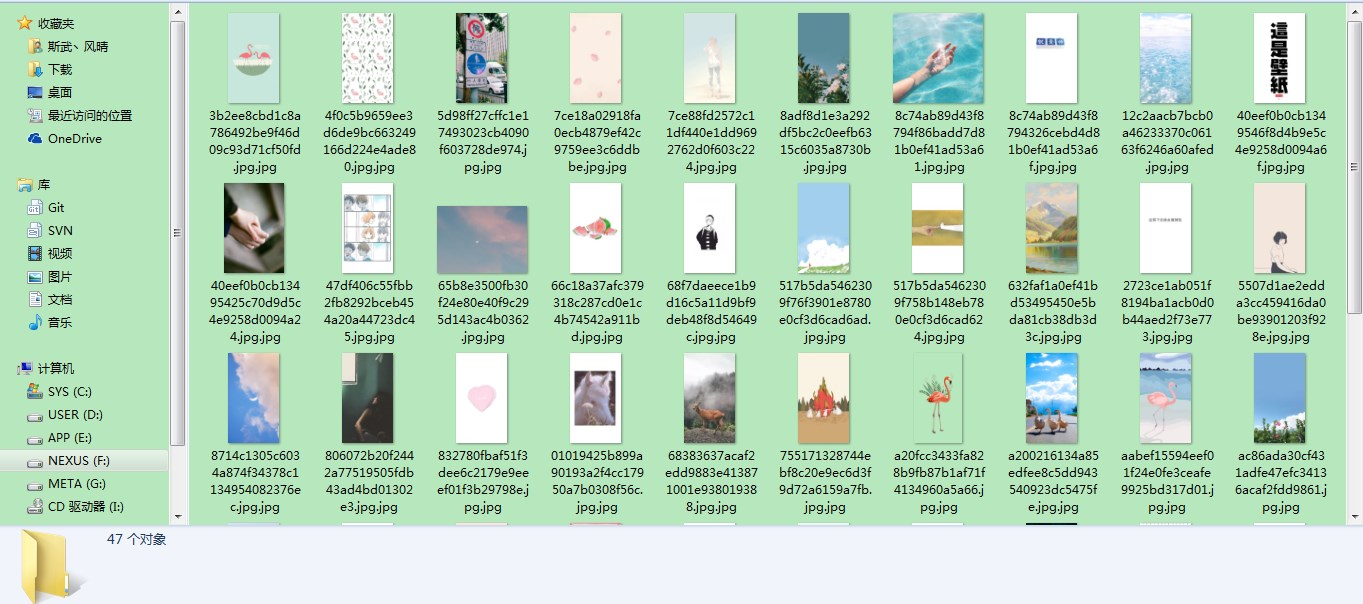
完整源码请见
我的github:
或码云:
by 斯武丶风晴